
本文主要分析了hadoop客户端read和write block的流程. 以及client和datanode通信的协议, 数据流格式等.
hadoop客户端与namenode通信通过RPC协议, 但是client 与datanode通信并没有使用RPC, 而是直接使用socket, 其中读写时的协议也不同, 本文分析了hadoop 0.20.2版本的(0.19版本也是一样的)client与datanode通信的原理与通信协议. 另外需要强调的是0.23及以后的版本中client与datanode的通信协议有所变化, 使用了protobuf作为序列化方式.
Write block
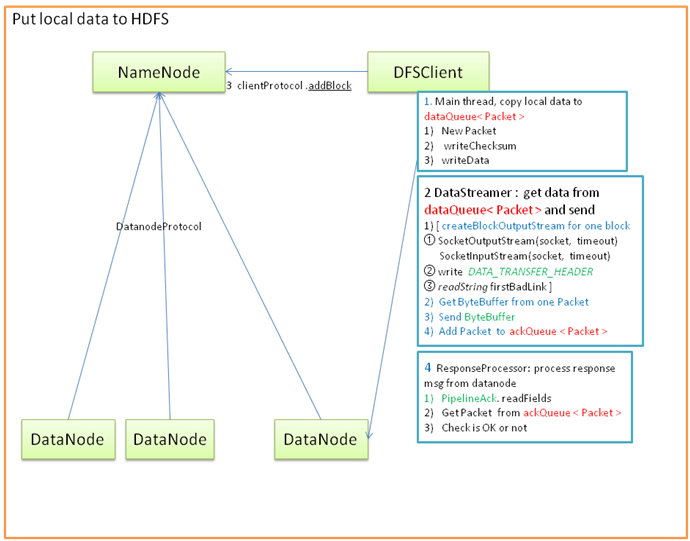
1. 客户端首先通过namenode.create, 向namenode请求创建文件, 然后启动dataStreamer线程
2. client包括三个线程, main线程负责把本地数据读入内存, 并封装为Package对象, 放到队列dataQueue中.
3. dataStreamer线程检测队列dataQueue是否有package, 如果有, 则先创建BlockOutPutStream对象(一个block创建一次, 一个block可能包括多个package), 创建的时候会和相应的datanode通信, 发送DATA_TRANSFER_HEADER信息并获取返回. 然后创建ResponseProcessor线程, 负责接收datanode的返回ack确认信息, 并进行错误处理.
4. dataStreamer从dataQueue中拿出Package对象, 发送给datanode. 然后继续循环判断dataQueue是否有数据…..
下图展示了write block的流程.
{kind=link}
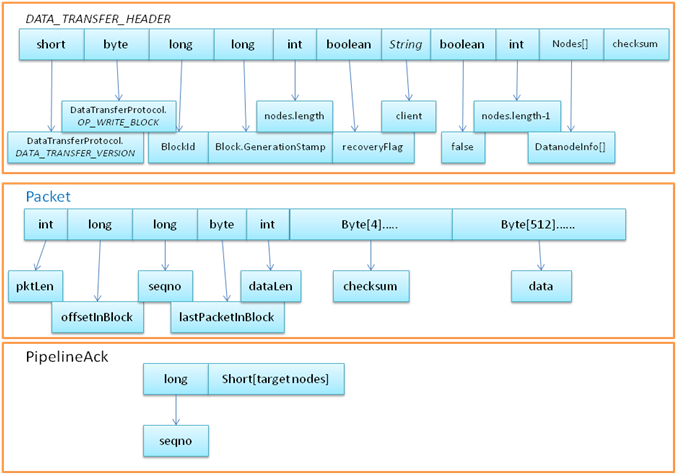
下图是报文的格式
{kind=link}
Read block
主要在BlockReader类中实现.
初始化newBlockReader时,
1. 通过传入参数sock创建new SocketOutputStream(socket, timeout), 然后写通信信息, 与写block的header不大一样.
//write the header.
out.writeShort( DataTransferProtocol.DATA_TRANSFER_VERSION );
out.write( DataTransferProtocol.OP_READ_BLOCK );
out.writeLong( blockId );
out.writeLong( genStamp );
out.writeLong( startOffset );
out.writeLong( len );
Text.writeString(out, clientName);
out.flush();
2. 创建输入流 new SocketInputStream(socket, timeout)
3. 判断返回消息 in.readShort() != DataTransferProtocol.OP_STATUS_SUCCESS
4. 根据输入流创建checksum : DataChecksum checksum = DataChecksum.newDataChecksum( in )
5. 读取第一个Chunk的位置: long firstChunkOffset = in.readLong()
注: 512个字节为一个chunk计算checksum(4个字节)
6. 接下来在BlockReader的read方法中读取具体数据: result = readBuffer(buf, off, realLen)
7. 一个一个chunk的读取
int packetLen = in.readInt();
long offsetInBlock = in.readLong();
long seqno = in.readLong();
boolean lastPacketInBlock = in.readBoolean();
int dataLen = in.readInt();
IOUtils.readFully(in, checksumBytes.array(), 0,
checksumBytes.limit());
IOUtils.readFully(in, buf, offset, chunkLen);
8. 读取数据后checksum验证; FSInputChecker.verifySum(chunkPos)